
Part of my role as CTO of Remade AI is working on diffusion models, the new generation of which are Latent Diffusion Models (LDMs). These models operate in a compressed latent space and VAEs are the things that do the "compressing" and "decompressing." An interesting byproduct of working with such models is that my cofounders have often found me in the office at 2am staring at the screen muttering to myself "What the F*** is a VAE?" This blog post is my attempt to answer that question!
What are Autoencoders?
An autoencoder is a type of neural network that learns to reconstruct its input data . It has two main components:
- Encoder (): Compresses into a lower-dimensional latent representation , where typically .
- Decoder (): Reconstructs (or "decodes") the latent vector back into , an approximation of the original input.
Putting it all together, a forward pass through the autoencoder typically looks like:
During training, we want to be as close as possible to . A common way to measure the difference between and is through a mean squared error (MSE) loss:
Hence, the autoencoder is typically trained by minimizing the sum of these reconstruction losses across all data points:
where and are the parameters of the encoder and decoder, respectively, and is the number of training samples.
Because the latent dimension is strictly less than the input dimension , the network is forced to learn a compressed representation of the data. This process:
- Encourages dimensionality reduction: The encoder-decoder structure is somewhat analogous to a learned, potentially nonlinear version of principal component analysis (PCA).
- Extracts features: The latent code often captures relevant factors of variation in the data.
However, classic autoencoders mainly focus on reconstruction and do not impose structure on to enable generation of new data from scratch. To address this, we introduce a probabilistic perspective on the latent space in the variational autoencoder (VAE), ensuring a smoother and more meaningful latent distribution suitable for generative modeling.
Variational Autoencoders (VAEs)
A variational autoencoder (VAE) can be understood as a latent variable model with a probabilistic framework over both observed data and hidden (latent) variables . Instead of deterministically mapping to a single point , a VAE places a distribution over conditioned on and imposes a prior distribution on itself.
We assume our data (e.g., images) are generated by a two-step probabilistic process:
where:
- is the prior over latent variables. Commonly, is chosen to be a simple Gaussian .
- is the likelihood model (decoder), parameterized by (e.g., a neural network).
Hence, the joint distribution factorizes as:
We are often interested in the posterior distribution , i.e. how the latent is distributed once we have observed data . By Bayes' rule:
but (the evidence) involves an integral over all possible :
which is typically intractable for high-dimensional or richly-parameterized neural networks.
To circumvent this, we introduce a tractable approximation , where are the variational parameters (often another neural network, sometimes called the encoder). We want to be "as close as possible" to the true posterior .
A standard choice is to let be a Gaussian (e.g. ), whose mean and (diagonal) covariance come from a neural network.
Learning by Maximizing the Evidence Lower Bound (ELBO)
We define the variational lower bound (ELBO) on :
Thus, the VAE objective is:
By optimizing this lower bound, we simultaneously:
- Maximize reconstruction quality (the first term, )
- Regularize the latent space (the second term, the KL divergence to a simple prior)
With a well-regularized latent space, we can sample new data by:
thus generating novel outputs in the data space. This property makes VAEs a powerful approach for generative modeling—each latent vector decodes into a coherent sample .
Disentangled VAEs (and Why We Care)
A disentangled variational autoencoder aims for each latent dimension (or a small subset thereof) to correspond to a single factor of variation in your dataset. In other words, we'd love each axis in to capture a different interpretable property, for example line thickness or tilt, without mixing those properties in the same dimension.
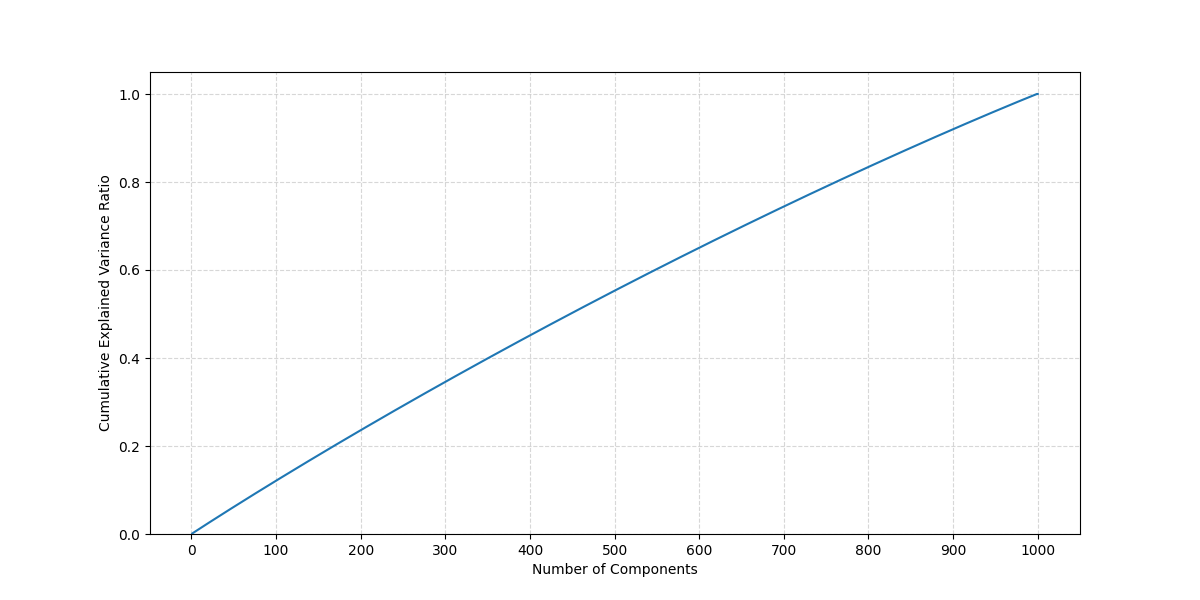
In an ideal disentangled latent space, we might see that a few principal axes explain most of the variance near an encoded point . But in practice, the Flux VAE, we observe from Figure 3 that the cumulative explained variance follows a logarithmic-like climb, implying no single dimension (or handful of them) dominates.
Since the curve has no clear "elbow," it suggests these latent spaces are quite entangled e.g. the variance is spread out, with no single direction accounting for a big chunk of variation.
To visualize whether certain directions in latent space produce coherent changes, we took the top 5 PCA components from that local neighborhood and stepped along each direction. Then, for each step in these directions, we decode back to image space.
The Flux VAE shows somewhat "random" or "flickering" transformations. In Figure 4 (the accompanying GIF), the reconstructions look mostly like noise or small chaotic changesindicating these latent directions do not correspond to a single factor (e.g., shape or color).
Conditioned Beta-VAE (on MNIST)
We can still find ways to achieve partial disentanglement, especially on simpler or labeled data. Below is an interactive demo of a Conditioned Beta-VAE trained on the MNIST dataset:
- "Conditioned" means we feed the digit class label along with the image into the encoder and decoder. This helps the VAE to separate label-driven variation from other variation.
- "Beta" means we scale the KL term by , pushing the model to compress the representation more aggressively and (hopefully) isolate distinct factors in separate latent dims.
Mathematically, the Conditioned Beta-VAE modifies the usual VAE objective. If we denote the data-label pair as , and the latent as , we have:
Here, is the encoder distribution (mean & log-variance come from a neural net that sees both and label ). Similarly, the decoder can incorporate the class label as an additional input.
We set to some value > 1 to further encourage the distribution over to stay close to a factorized Gaussian prior, yielding disentangled latents if the data factors are suitable.

The demo below runs entirely client-side using ONNX Runtime Web. I first trained the model in PyTorch, saved it as a safetensors checkpoint, then converted it to ONNX format using torch.onnx.export. The resulting ONNX model is loaded directly in the browser via onnxruntime-web, which provides efficient inference without any server calls. When you interact with the demo, dimension #3 of the latent space shows clear control over the digit's tilt - a nice example of disentanglement!
Adjusting dimension
Disentangled Latent Spaces and Diffusion Models
Latent diffusion models (LDMs) run the diffusion process in a compressed latent space rather than raw pixels. If that latent space is disentangled, the diffusion process can manipulate distinct factors more easily. For instance:
- The diffusion model might add noise along a specific dimension that strictly corresponds to "stroke thickness," letting you generate new samples with controlled variation of that factor.
- A structured latent space often allows fewer steps or easier sampling, as the factors are not entangled in complex ways the model has to "untangle."
That said, training-time trade-offs arise. Pushing for disentanglement (often via a bigger ) can increase the model's complexity, slow down training, and sometimes degrade raw reconstruction quality. But if the final goal is a stable, controllable latent space (like for LDMs), it might be worth the extra training overhead.
In short, a well-disentangled VAE helps us push the diffusion process into a more interpretable and manipulable domain enabling easy factor-specific editing or exploration. Of course, in large real-world datasets (like images from the web), achieving full disentanglement is tricky. But even partial disentanglement, as shown in our MNIST or toy examples, can significantly improve the user control and semantic clarity of generative pipelines.
References
- View code here
- Multi-view hierarchical Variational AutoEncoders with Factor Analysis latent space.
- Variational Autoencoders Pursue PCA Directions (by Accident).
- Disentangling VAE: Experiments for understanding disentanglement in VAE latent representations.
- Disentangling by Factorising: A method that improves upon β-VAE by encouraging factorial latent representations.
- Disentangling Disentanglement in Variational Autoencoders: A unified theoretical framework for analyzing and improving representations.
- Learning Disentangled Representations with Variational Autoencoders: A comprehensive overview of VAEs and disentanglement.